
Dataset Viewer
The dataset viewer is not available for this subset.
Cannot get the split names for the config 'default' of the dataset.
Exception: SplitsNotFoundError
Message: The split names could not be parsed from the dataset config.
Traceback: Traceback (most recent call last):
File "/usr/local/lib/python3.12/site-packages/datasets/inspect.py", line 286, in get_dataset_config_info
for split_generator in builder._split_generators(
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/datasets/packaged_modules/json/json.py", line 91, in _split_generators
pa_table = next(iter(self._generate_tables(**splits[0].gen_kwargs, allow_full_read=False)))[1]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/datasets/packaged_modules/json/json.py", line 194, in _generate_tables
json_field_paths += find_mixed_struct_types_field_paths(examples)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/datasets/utils/json.py", line 58, in find_mixed_struct_types_field_paths
examples = [x[subfield] for x in content if x[subfield] is not None]
~^^^^^^^^^^
KeyError: 'reasoning_trace'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/config/split_names.py", line 65, in compute_split_names_from_streaming_response
for split in get_dataset_split_names(
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/datasets/inspect.py", line 340, in get_dataset_split_names
info = get_dataset_config_info(
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/datasets/inspect.py", line 291, in get_dataset_config_info
raise SplitsNotFoundError("The split names could not be parsed from the dataset config.") from err
datasets.inspect.SplitsNotFoundError: The split names could not be parsed from the dataset config.Need help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
prompt_completion_pairs
A dataset of prompt-completion pairs covering diverse topics such as technology, language, poetry, and science. Each entry consists of a user prompt and a corresponding generated response. The data reflects instructional, explanatory, and creative query patterns.
This dataset is a remastered version of this dataset prepared using Adaption's Adaptive Data platform.
Quality of Remastered Dataset
The final quality is B, with a relative quality improvement of 45.0%.
Domain
- Science (18%)
- Language (12%)
- Code (10%)
Language
- English (100%)
Tone
- Explanatory (34%)
- Informative (24%)
- Practical (8%)
Evaluation Results
Quality Gains:
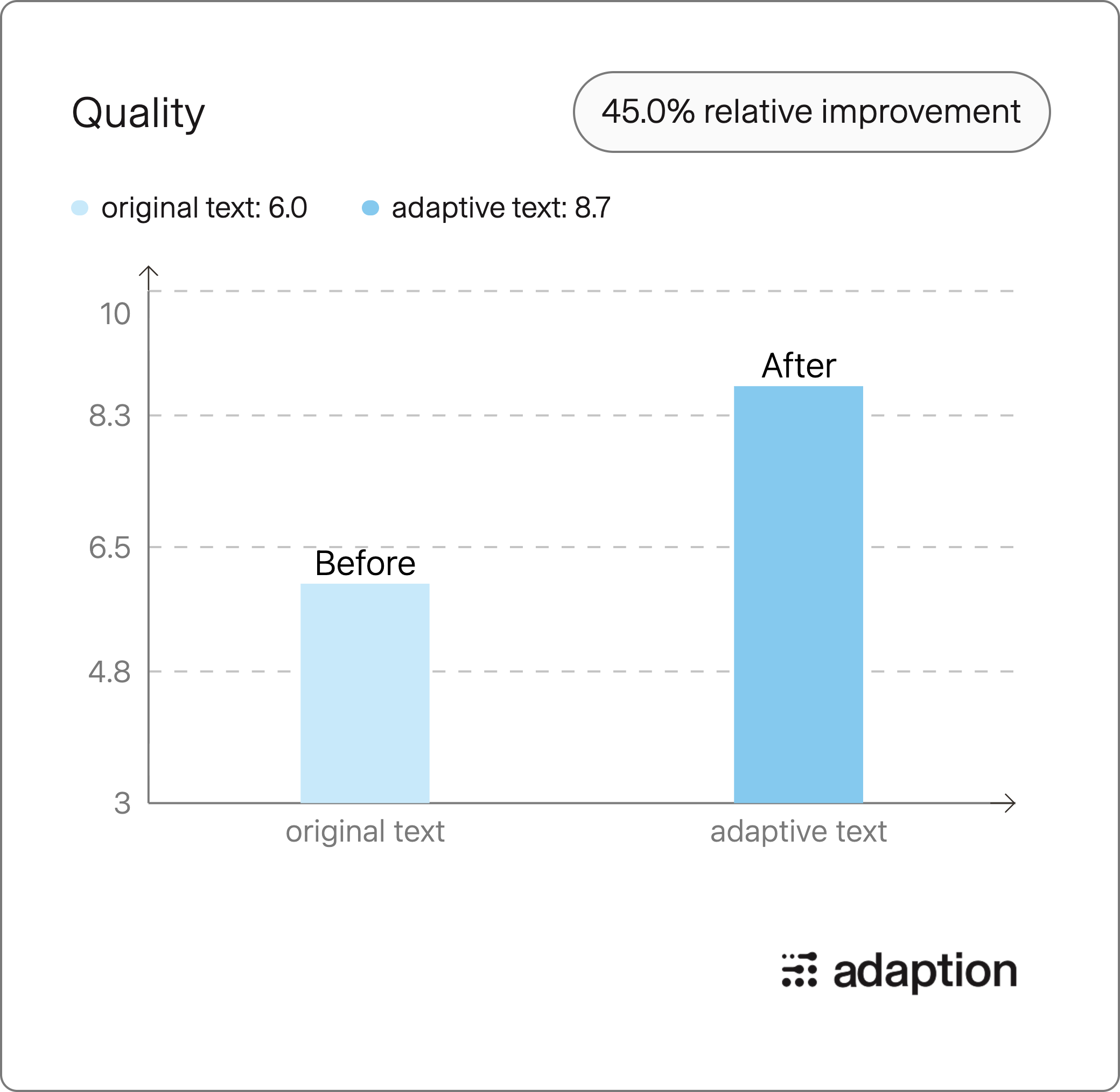
Grade Improvement:

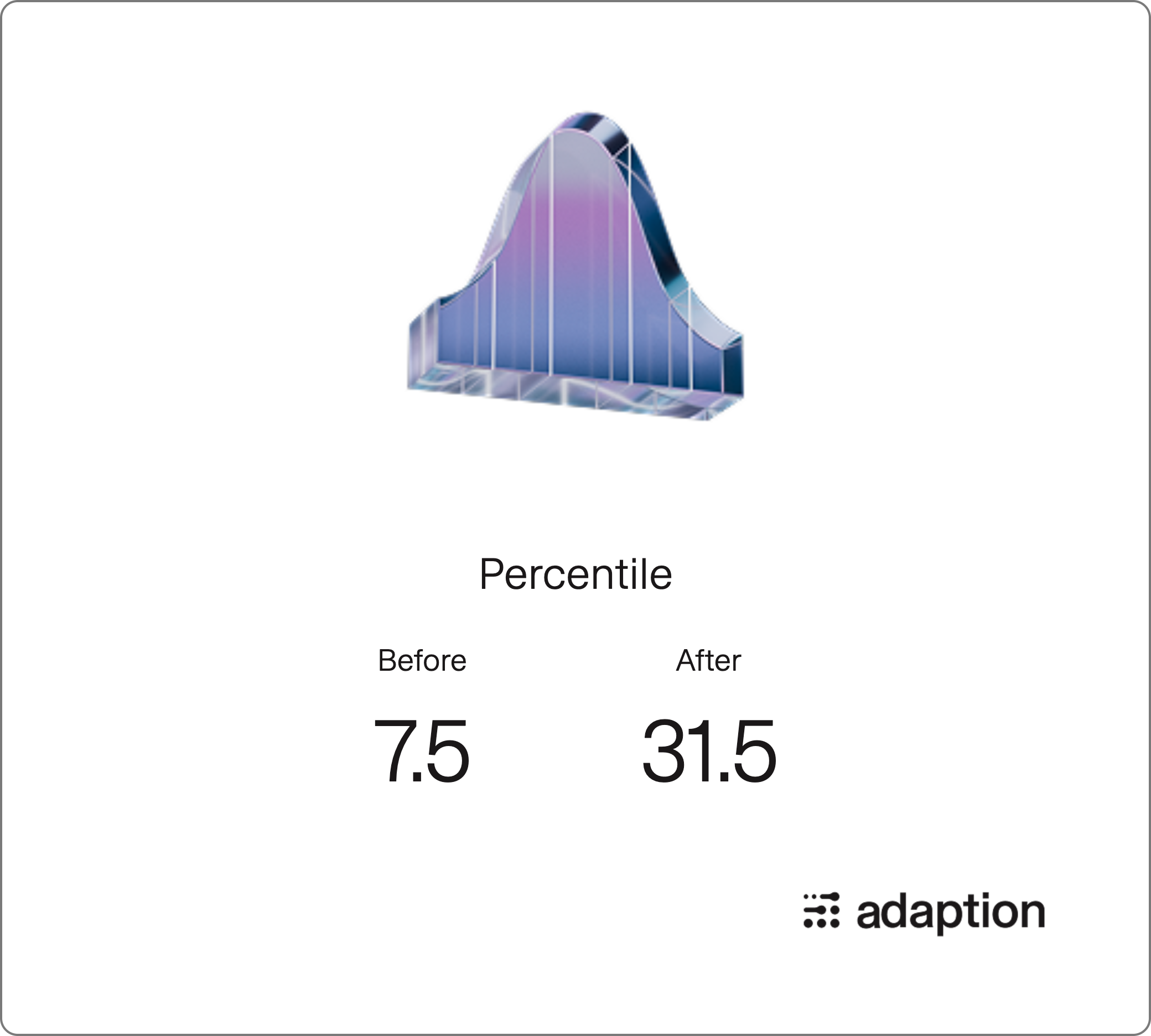
Percentile Chart:
- Downloads last month
- 13